从去年到今年,国内几家新势力和供应商(华为、元戎、Momenta等)纷纷喊着要上“端到端”智驾,并将其作为2024下半年的工作重点。“端到端”是不是特斯拉首倡存在争议,但毫无疑问,特斯拉是第一个将其工程化和商业化的企业。
如果以“全量推送”为考核点,2024年3月,特斯拉在北美推送FSD V12正式版。但在中国落地,仍在走流程。这给了国内很多企业说自己不亚于、甚至在中国强于特斯拉智驾模型的机会。
7月30日,小鹏向全球推送AI天玑系统XOS 5.2.0版本;
9月11日,华为鸿蒙智行推送ADS3.0。有意思的是,无论哪个界,都在大谈“端到端”的时候淡化了“华为”;
10月23日,理想推送了“端到端+VLM”,声称行业首创。理想的确是第一个将二者实际结合的品牌;
蔚来稍微落后一点,高调发声的“世界模型”尚未落地——7月份推出了包含个别功能的Demo版。
一个人脑决策的模拟
既然“端到端”这么时髦,到底什么是“端到端”( End-to-End, E2E)?抱歉,没有公认的准确定义,就像端到端的机理一样,基本上属于自拉自唱的节目。
低情商解释——“端到端”是实现智驾的一条技术路线。智驾从CNN、RNN、GAN、到Transformer大模型(典型应用是城区轻图NOA),直到如今的端到端。“端到端”即将经典感知、规划、决策、执行多模块智驾,合成一体,由感知直接“生成”决策和执行。
看到“生成”俩字,就很容易理解,这和ChatGPT是一个路子,即建立一个茫茫多参数(可能多达100B以上,1B=10亿)模型,通过强大算力,不断用数据训练这个模型,期待它产生明智的决策,无论下一个新场景,它有没有碰到过。这样一来,端到端其实就是用大模型的方式,来解决智驾的长尾(罕见场景)问题。
高情商解释——不了解上文那一大堆缩写?没事!比如你牛马附体,驾车下班路上还不断打电话处理公务,不知不觉就开回家了,回头都想不起怎么回的家。这一路的驾驶行为,就是端到端。
说白了,就是试图用大模型模拟人脑的决策方式,明智地处理无穷无尽的新场景。
有些人觉得这一通解释,说了跟没说一样。其实这么想有道理,这很像“将大象推入冰箱”的任务,开门关门都非常清楚(因为符合人的生活经验),但对于将大象推进去的关键步骤,却语焉不详。
不怪搞技术的,因为的确说不清楚。他们的解释是“可解释性差”,气人不?
但是不着急,之于用户,对于端到端的推崇以及呼声,从一个窄众群体(发烧友以及智能爱好者们)到当下全民,越来越有成为全民兴奋点的趋势。端到端的全量推送,对国产品牌高度关注的用户们,讨论度一点都不比投资者们少,他们在期待某种意义的反击(虽然他们获取或者了解的信息量参差不齐)。
目前人类的技术,感知没问题,决策到执行段也没问题。如何从感知到决策,有大问题。人脑是怎么思考的,大家其实不知道。但原则是“经验决定预测”,这是当前人类驾驶比AI强的地方。一个数理逻辑不好的人,甚至没太多文化的人,也能开好车,就是这个道理。端到端省去了规控这一块,直接决策,反馈加快了,企业希望决策准确度不降反升。
保守派和原教旨派
有人提出,端到端的本质应当是感知信息的无损传递,虽有道理但难懂。其实端到端的精髓,莫过于考虑如何不用规则来思考。这并非指抛弃交通规则,而是无需程序员事先对每一个可能场景编好应对方案,AI自己就会基于眼前场景找到最优答案。因此,可以将端到端近似描述为“基于经验和基础规则的预测模型”。
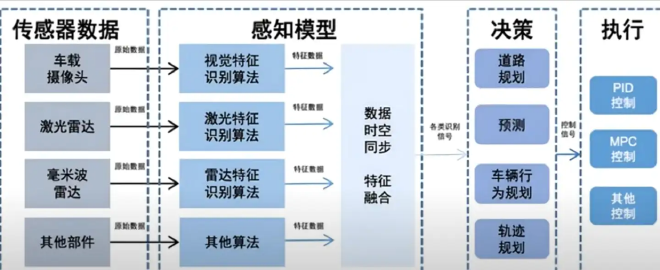
(经典规控模型)
端到端之前的智驾方案,都是多个模块的组合。感知、规划、控制都是独立的。信息在串联模块当中传递有延迟和数据缺失,而且误差的逐级积累,也可能带来安全隐患。
理论上,端到端应该将三者合一,消除内部数据接口。但是,小鹏、极越等“保守派”仍实行两段式“端到端”,即将感知和规控分为两个模型。小鹏前者叫Xnet(感知神经网络),后者叫规划神经网络(XPlanner)和视觉语言模型(VLM)XBrain。
而原教旨派则认为“两段式”没有脱离传统智驾的窠臼,即两个网络中间,仍然是人工定义的接口。传统智驾的信息漂移、延迟的毛病都继承下来了(尽管有改善)。
两段式的好处在于,既然人类定义了中间接口,人类就能看懂中间结果,便于检查系统、找出毛病。比如感知出了问题,不用将整个系统用“好数据”重新训练。也容易兜住系统下限,避免出现令人匪夷所思的错误。
但是,10月23日理想公布的“4D One Model”和特斯拉一样,是一段式,即端到端+VLM。
VLM看来必不可少,其实也是个大模型。它可以从图像(交通场景)和文本(交通标识)中学习的多模态模型。简单说,输入了图像和文本,输出(生成)文本。这个文本用于规控模型来理解场景意义。
VLM和端到端模型本身的区别在于,它不用训练就具有泛化能力(当然能训练更好)。其最重要的工作在于,获取图像中的空间属性,即识别障碍和运动路径。
无论VLM,还是端到端大模型,都是黑盒子。人们不知道它怎么生成了认知和决策,就像不知道如何将大象推入冰箱一样,但看结果是推进去了。
这就是所谓的“可解释性低”。即决策逻辑可以理解,但过程不可理解。一旦决策结果出了问题,没别的办法,只能不断加大数据填喂量,调整模型参数,尽可能堆高模型准确率,但不保证100%安全。
必须承认,端到端同时扩张了智驾系统的上下限,这就是为什么有的企业跟风做端到端,训练了好久,发现系统表现反而更差了。这就麻缠了,因此需要“划红线”,比如绝对不能闯红灯等规则,明确到神经网络中去。这就是兜底原则。
大模型需要“奶妈”
建造和训练大模型,首先要很多钱。因为到了B级参数量级,连存储数据都很贵,匡论算力。
目前特斯拉超算中心的算力支持由D1芯片和超算Dojo组成。投资10亿美元,总算力100EFLOPs(1EFLOPs为每秒1018次浮点运算),这一部署尚未完成。
而智能云端算力的门槛大致为1EFLOPs,车企目前平均后台算力为3 EFLOPs。华为后台算力可能为7.5 EFLOPs。三大电信运营商的算力部署规划从15到21 EFLOPs不等。
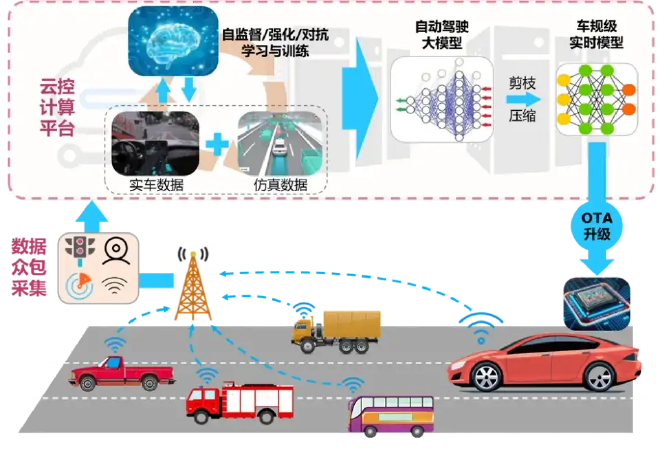
(端到端流程示意)
理想训练算力(不等同于总算力)为5.39 EFLOPs,由5000块计算卡组成(英伟达A100和A800)而一块用于训练生成式大模型的A100,报价10万元人民币,A800则至少在12万元以上。
显然,超算中心搭建必须有大资金支持,就算每月电费也可能高达数百万元。在汽车圈,今后几年内特斯拉用于训练的算力规模,显然是最大的。
有了硬件,还得有数据。数据量决定了训练质量。
7月份马斯克在财报会议上打的比方广为人知,他说FSD V12“训练了100万个视频案例,勉强工作;200 万个,稍好一些;300 万个,你就会感到,Wow;1000 万个,它将变得难以置信。”当然,老马作为传播教父,具体数据不用纠结,知道数据量与系统决策正确性正相关即可。
需要明确的是,“坏数据”(青涩的驾驶、糟糕的驾驶习惯、违反交通规则等)会“向下拖曳”大模型的训练效果。简单说,最好是理智守法克制的老司机。
特斯拉的影子驾驶,能扒到大量数据。训练的本质是模仿。仿着仿着就出徒了。那么问题来了,填喂数据的质量谁来保证?还是得人工审核。即便不是纯人工,也要做某种人工规则下筛选。就像无图(其实是轻图)同样要做人工标注一样。
堆人力资源也是昂贵的投资,且注定改善训练不会太快。高质量数据则意味着罕见场景+好数据。如果产品的保有量上不去,也意味着扒不到太多好数据,训练改善就慢,系统迭代就会落后于对手。
思路、投资和技术路径相似的前提下,产品保有量成了智驾水平最重要的致胜因素。那么,谁的算力投资大、路径清晰、产品的绝对保有量更大呢?结论呼之欲出。

(特斯拉FSD状态)
如是,端到端的“奶妈”是投资、数据、人力和耐心!
端到端的思路诞生于大模型和算力的突破,只是一条看似很有希望的路线。现在的问题是,训练到一定量级,系统改善可能遭遇瓶颈(训练量逐渐与效果脱钩)。现在走在前面的企业,可能都碰到了“数据墙”,但他们都讳莫如深。如今有人认为,既然力大砖飞,端到端模型参数到达100B(和ChatGPT4.0差不多量级),训练量到亿级,智驾水平会不会发生质的飞跃?
这个暂时还没人试过。在产生足够的经济回报之前,搭建这样的系统,怀疑荷包先撑不住。马斯克的“第一性”是好东西,但不等于马老师本人就是第一性。
从Transformer+BEV,到端到端,一直是国内第一梯队跟紧特斯拉思路,落后半年到1年,而第二梯队则落后特斯拉两年左右,即刚开始搭建系统。迄今为止,说特斯拉是智驾领路人,并不为过。而Waymo的Robotaxi,则没有产生这么大的影响力。现在特斯拉也开始鼓吹Robotaxi,国内车企是否继续跟进,也是看点。总体而言,大家都在围绕销量做文章。至于影响和塑造人类交通和生活方式这种宏大叙事,那得活下来的企业才有资格想这个问题。

更多汽车资讯,涨知识赢好礼扫描二维码关注(auto_sina)